Optimizing pysqlite/sqlite3 databases and queries: Part II: Scaling & Splitting (notes/outline for 2009 Nov 9 presentation to TuPLE -- edited post-presentation version)
Introduction
- “How does it scale?”
- Some general observations
- Some actual specific test data
- I will indicate sources of data and allegations
- me VS other people VS both
- Some motivations for this topic
- Judging when (py)sqlite is appropriate for a job
- Deciding when/whether splitting a database into multiple files
in attempt to speed some operations is worthwhile (klu(d)ge!)- e.g.
- Different table(s) in different database files
- Same table split between multiple database files
- e.g. each day’s data in a separate db file
- e.g.
Caveats
- I used default distribution of pysqlite (aka sqlite3)
with Python 2.5 and/or 2.6 for Windows, unless I say otherwise. - I indexed every table effectively for my queries, unless I specify otherwise.
- Each of my test sets was on some specific computer, generally slowish with
- ca. 500MB of RAM
- 1 to 2 GHz CPU speed (usually 1GHz)
- other tasks/processes roughly consistent
- but one exception I might mention.
Some References
- http://www.sqlite.org/version3.html
“SQLite Version 3 Overview” - http://www.sqlite.org/fileformat.html
“SQLite Database File Format” - http://www.sqlite.org/lockingv3.html
“File Locking And Concurrency In SQLite Version 3” - http://stackoverflow.com/questions/784173/what-are-the-performance-characteristics-of-sqlite-with-very-large-database-files
Includes some info re test results.- Poster “Snazzer” appears to have implemented
a simple splitting of a table’s contents into multiple db files.- Some scaling benefits obtained
- Poster “Snazzer” appears to have implemented
- http://www.sqlite.org/speed.html
Officially outmoded speed tests- small scale IMHO: the only documented numbers are <=25000 rows.
- http://www.sqlite.org/cvstrac/wiki?p=PerformanceConsiderations
- Includes “Charles Thayer” test report
- specs:
- Linux 2.4.22
- sqlite 3.0.8
- ext2 on IDE drives
- Dual Pentium 4 @ 2.6GHz
- 1 GB RAM
- specs:
- Includes “Charles Thayer” test report
How Does it Scale?
Some Theory
- SQLite uses
- btrees for managing blocks of space in its internal file format
- btrees for indexes (indices?)
- One would hope that many activities would be O(log n)
- SQLite also uses
- caching
- behaves like some caching exists
- disk caching is almost inevitable even without SQLite trying to
- virtual memory
- could slow if
- massive db files
- little RAM available
- other activities/processes are greedy
- could slow if
- caching
- We can assume most or all tables are indexed because:
- If you care about performance, you probably index
- File locking:
- multiple processes can read a db file at same time
- one process can write only by locking others out of writing, reading
- (more details at http://www.sqlite.org/lockingv3.html if you care.)
- Exception: “a limited form of table level-locking”
- limited support for splitting a db between files
using ATTACH command.- ATTACH permits multiple db files to be temporarily
treated as being within the same db. - a db can be somewhat split between multiple files
using ATTACH.
(see e.g. http://www.sqlite.org/version3.html) - Docs assumption is that a
table can’t readily be split between files using ATTACH.- (But we can think of ways that are ugly-hacky,
e.g. tables with same definition except
different names, specially hacked-up queries…)
- (But we can think of ways that are ugly-hacky,
- ATTACH permits multiple db files to be temporarily
- limited support for splitting a db between files
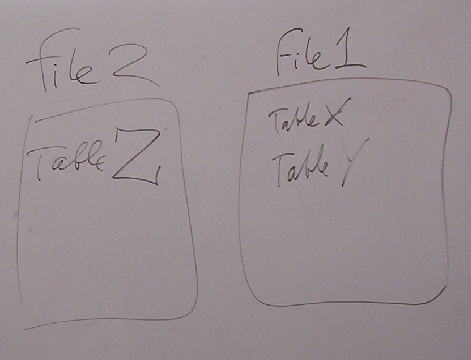 |
| Different database files may temporarily be treated as part of the same database using SQLite’s ATTACH command. (drawing on whiteboard during my talk) |
Some Practical Observations and Test Data
- Much of the commentary available on how SQLite scales is rather vague
- Examples
- “If you need to store and modify more than a few dozen GB of data,
you should consider using a different database engine.” - “I’ve created SQLite databases up to 3.5GB in size
with no noticeable performance issues.”- from the stackoverflow.com page in References section.
- stackoverflow.com poster “Snazzer” reports test results
- “Single Table”
- tried to insert 50GB of data into sqlite file with one table
- insertions became “far too” slow by 7GB.
- “…the VACUUM command is a problem
the larger the sqlite file is.”
- “If you need to store and modify more than a few dozen GB of data,
- Examples
- Size of an index
- An index on a table can sometimes be a significant fraction
of table’s own size- e.g. I’ve seen ca. 1/3 to 1/2 for index on 2 columns of a table.
- An index on a table can sometimes be a significant fraction
- Insert rows on indexed table:
- Many rows per transaction:
- time for a row within that transaction does look plausibly O(log n)
- where n = number of rows in table (or size of db?)
- e.g.
- [Test on 2009-10-11 to 2009-10-12;
db size 586,346K: a little larger than total RAM]- example figures from db size near size of total RAM:
- insert indexed row
- I used standardized code & transaction bundling in test
- table has
- string column (usually <16 characters)
- integer column (happen to be <30,000)
- 3 explicitly created indices
- Inserted 7.7 million rows
- Measured insertion rate declined by ca. 4x
- from 23800 rows/min (397 rows/sec) avg.
for first 500,000 rows - to 5900 rows/min around 7.5 million rows.
- from 23800 rows/min (397 rows/sec) avg.
- Measured insertion rate declined by ca. 4x
- table has
- I used standardized code & transaction bundling in test
- [Test on 2009-10-11 to 2009-10-12;
- time for a row within that transaction does look plausibly O(log n)
- Many rows per transaction:
 |
- Some factors might, I hypothesize, reduce scaling effect
- Sources of overhead
- Separate transaction for each row inserted
- MAYBE:
- ?reduction in proportion of insert
that consists of updating indices?
- ?reduction in proportion of insert
- e.g.
- a wiki says :-) Charles Thayer tested in 2005 inserting
http://www.sqlite.org/cvstrac/wiki?p=PerformanceConsiderations- conditions
- 8 million rows
- 1.6 GB table size
- results
- 72/second to 34/second slowdown
- His performance starts out slower than in my test.
- Another commenter on wiki wondered
how he got such slow performance. :-)
- conditions
- a wiki says :-) Charles Thayer tested in 2005 inserting
- Sources of overhead
- Select rows from indexed table:
- In my quick & dirty test attempt,
- Used well-indexed databases with sizes
- 0.5 million rows (~37MB)
- 1 million rows (~75MB)
- 7.7 million rows (~586MB)
- Used various queries:
- simple select on ~2 criteria without join
- self-join
- self-join on self as ‘3’ tables
- In most selects finding only a few rows,
overhead and ‘background noise’ seemed to swamp any scaling effects.- overhead: e.g. opening & closing db connection, cursor
- usually total time was .08 seconds to 1 second
- only neared or exceeded 1 second if hundreds of rows were selected.
- " " " 2 to 4 seconds if thousands " " "
- In these specific tests,
visible select time growth was less than O(n)- whether n is rows in db OR rows selected.
- Used well-indexed databases with sizes
- In my quick & dirty test attempt,
- I didn’t have spare time to make more, larger test dbs.
- so slowing of inserts as db, table grows did cause inconvenience.
- I don’t have any nice graphs and charts ready for you.
- select count(*)…
- reportedly O(n) scaling re Charles Thayer
- ca. 50,000 rows/second
- I saw on slower machine, different table
- on 0.5M row table, 7.7M row table
- ca. 7000-8000 rows/second
- I did not time the selects precisely enough
to check for tiny slowdown- slowdown if any was roughly between -0% and 15%.
- reportedly O(n) scaling re Charles Thayer
- Whole-db operations can scale O(n2) or worse
- Index creation:
- I’ve seen 10-fold increase in table size
cause 140-fold increase in time to create 2-column index.
[large index test 2009-08-19
on ca. 450MB db vs. 10-shard split.
Index on 2 columns of table.] - vacuum is also kind of horrible
- but I don’t know where I might have written data, sorry.
- I’ve seen 10-fold increase in table size
- Index creation:
Conclusion
- Some sqlite db scaling characteristics:
- “n” here is table size in rows
(but maybe a db much bigger than table could additionally affect) - btrees are used heavily in sqlite db format implementation
- inserts:
- indexed:
- Most important case
- probably O(log n)
- can worsen noticeably
over the first 1/2 to several million rows size range
- indexed:
- selects
- well-indexed:
- up to several million rows in table:
- efficient enough that overhead, background
can swamp scaling effects. - in example, 0-4 seconds to select thousands of rows
on slow computer. - can sometimes appear better than O(n).
- efficient enough that overhead, background
- up to several million rows in table:
- well-indexed:
- Whole-db operations
- create index on existing rows can be worse than O(n2)
- vacuum also seems pretty bad
- “n” here is table size in rows
- This data might help you
- decide when to use SQLite
- know what to expect of it
- figure out when/how to use hacks/kludges
like splitting a table into multiple db files
(“same-machine sharding” / “same-box sharding”).
The End